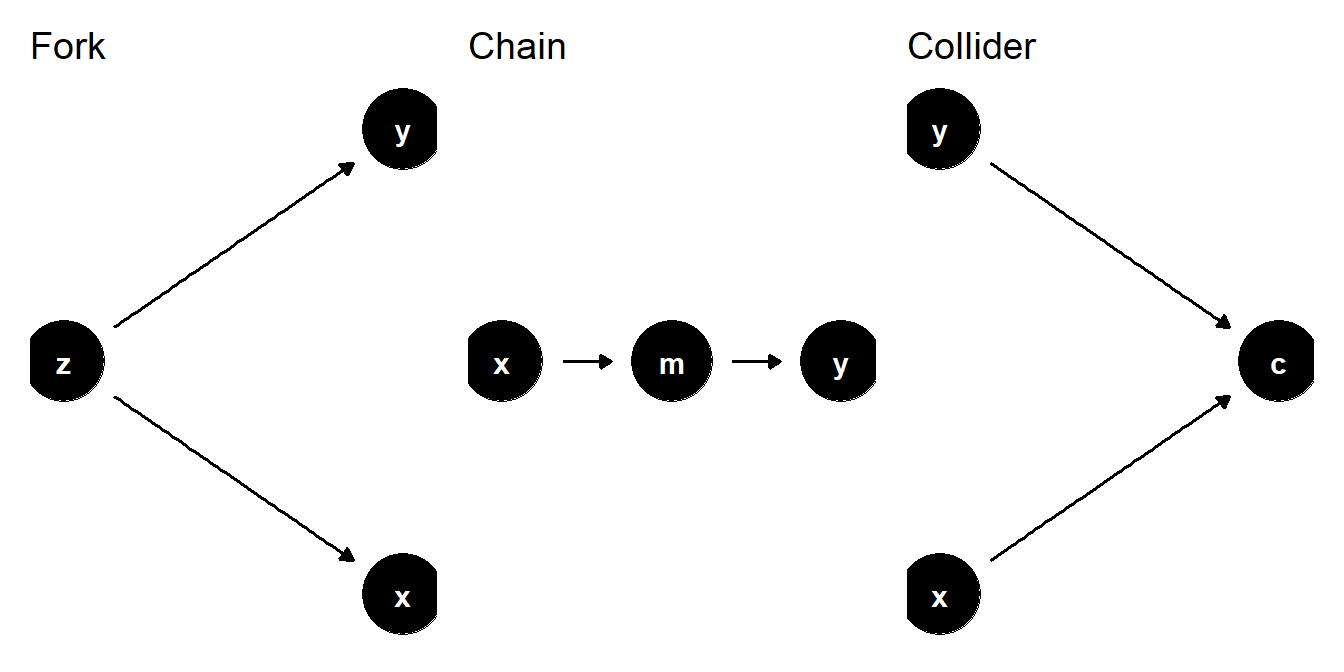
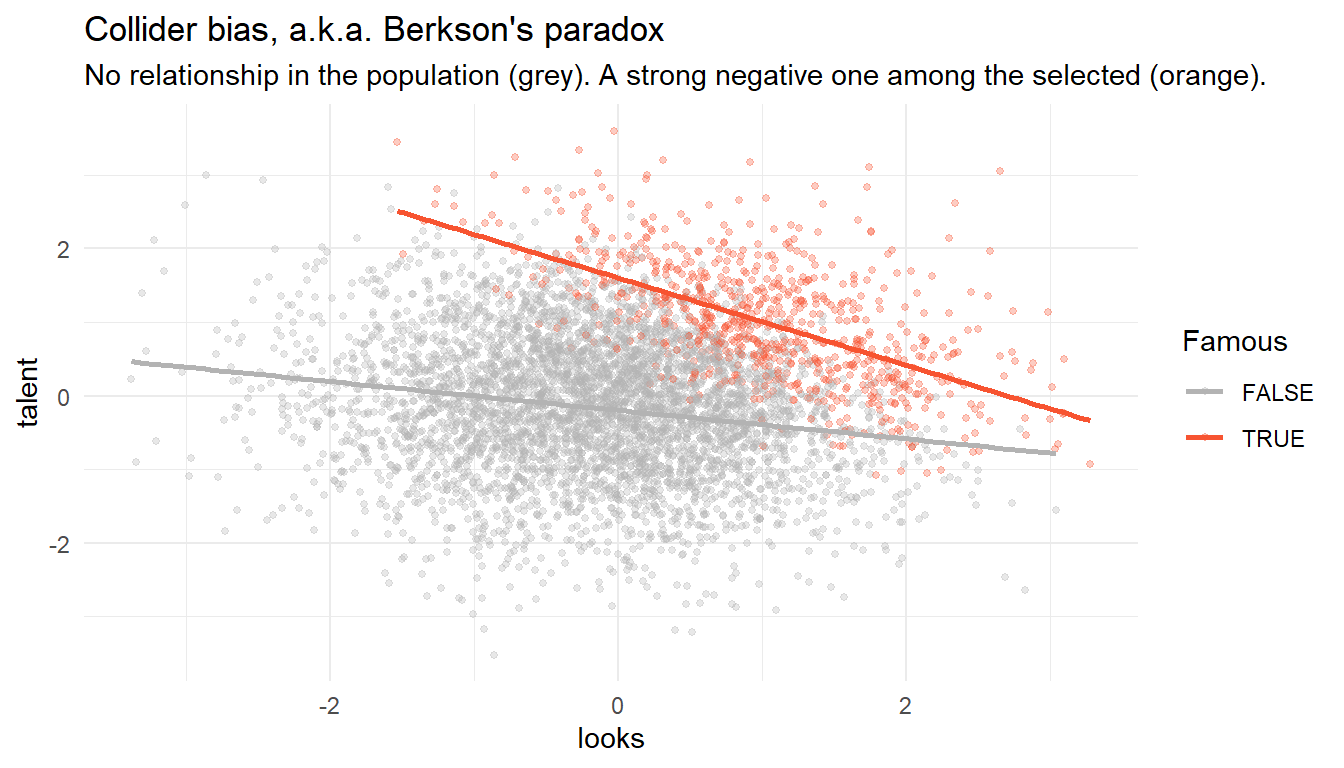
{
const donorLines = scSeries.donors.flatMap(d => d.vals.map((v, i) => ({j: d.j, t: i + 1, y: v})));
const tr = scSeries.treated.map((v, i) => ({t: i + 1, y: v}));
const sy = scFit.synth.map((v, i) => ({t: i + 1, y: v}));
const ymax = 28 + 8 * sc_unique;
return Plot.plot({
width: Math.min(width, 780),
height: 420,
x: {domain: [1, 18.4], label: "Time", ticks: d3.range(1, 17, 3)},
y: {domain: [0, ymax], label: "Outcome", grid: true},
marks: [
Plot.ruleX([10.5], {stroke: "currentColor", strokeDasharray: "3 3", opacity: 0.5}),
Plot.text([{x: 10.5, y: ymax * 0.97}], {x: "x", y: "y", text: ["policy →"], dx: 6, textAnchor: "start", fill: "currentColor", opacity: 0.6, fontSize: 11}),
Plot.line(donorLines, {x: "t", y: "y", z: "j", stroke: C.ghost, strokeWidth: 1, opacity: 0.35}),
Plot.text([{t: 2.2, y: donorLines[1].y}], {x: "t", y: "y", text: ["donor pool"], dy: -12, fill: C.ghost, fontSize: 11}),
Plot.line(tr, {x: "t", y: "y", stroke: C.treat, strokeWidth: 2.6}),
Plot.line(sy, {x: "t", y: "y", stroke: C.ctrl, strokeWidth: 2.2, strokeDasharray: "6 4"}),
Plot.text([tr.at(-1)], {x: "t", y: "y", text: ["treated"], dx: 8, textAnchor: "start", fill: C.treat, fontWeight: 600, fontSize: 11.5}),
Plot.text([sy.at(-1)], {x: "t", y: "y", text: ["synthetic"], dx: 8, dy: 12, textAnchor: "start", fill: C.ctrl, fontWeight: 600, fontSize: 11.5}),
Math.abs(tr.at(-1).y - sy.at(-1).y) > 0.4
? Plot.arrow([{}], {x1: 16.6, y1: sy.at(-1).y, x2: 16.6, y2: tr.at(-1).y, stroke: "currentColor", strokeWidth: 1.6})
: null,
Plot.text([{x: 16.75, y: (tr.at(-1).y + sy.at(-1).y) / 2}], {x: "x", y: "y", text: [`gap = ${fmt(scFit.gap)}`], textAnchor: "start", fontWeight: 700, fontSize: 11.5, fill: "currentColor"})
]
});
}