Learn how to transform information stored in text as data you can analyse and visualise
text
sentiment
ngrams
pdf
book
network
regex
wordcloud
Import, clean, tokenise and stem text, plus do sentiment analysis, topic modelling and learn how functions in R make your work so much easier.
Author
Nelson Amaya
Published
July 31, 2022
Modified
November 22, 2024
“For every complex problem there is an answer that is clear, simple, and wrong.” –H.L. Mencken
Text analysis is how you convert prose into a numerical analysis. Examples of applications of text analysis are Google NGrams and translators like DeepL. It is also a building block for AI applications, like the recently released ChatGPT.
In this session we will focus on retrieving, cleaning and visualising text data.
PART I: Text to data
To get us started, we need to learn how to transform and clean text data. We’ll use an example of a book as a warm up.
Breaking down “The Origin of Species”
We’ll use Charles Darwin’s “On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life” to illustrate how to go from text to data.
We first download a PDF copy of the book online (like this one). Then, using the pdftools package, we can import the text into R. PDF is a terrible format to store data, you’ll see why soon.
TipRegular expressions, regex
Regular expressions are a way to specify or search for patterns of strings using a sequence of characters. By combining a selection of simple patterns, we can capture quite complicated combinations of strings.
library(pdftools)library(tidytext)library(tidyverse)# Read the whole book using PDF tools package #### "/sessions_workshop/03-text/"the_origins_of_species <- pdftools::pdf_text(paste0(getwd(),"/Darwin-1859 Origin of Species.pdf")) |> stringr::str_squish()
1
Read the file into R with the function pdf_text()
2
Eliminate all blank spaces in the text
Working with text-as-data: Tokenization, stopwords, stemming
Before we can actually use the text to analyse it, we need to perform a few operations. The first is to create tokens, which is basically the unit of measurement we choose for our text analysis. Token can be words, characters, sentences, paragraphs, n-grams, you name it. To tokenize the book, we’ll use a function from the tidytext package that does all the heavy lifting for us.
TipA sliver of regex
regex gives headaches, and the 2nd page of the stringr cheatsheet is your ibuprofen. There are a few important operations in regex you should remember:
Special metacharacters
\. Represents a period. To match a period, type \\.
\\ Represents a single backslash. To match two backslashes, type \\\\
\" Represents a single quotation sign.
\n New line
Anchors
^ Start of the string
$ End of the string
\\b Empty string at either edge of a word
Stop! Removing words we don’t care much about
We will then extract words from the remaining data that we won’t need. These are called stopwords, and include a list a articles, propositions and other words that we are not super interested in analyzing. We will remove the words using the anti_join() function, which removes any common elements from two databases.
Looking for the root and a bit of linguistics
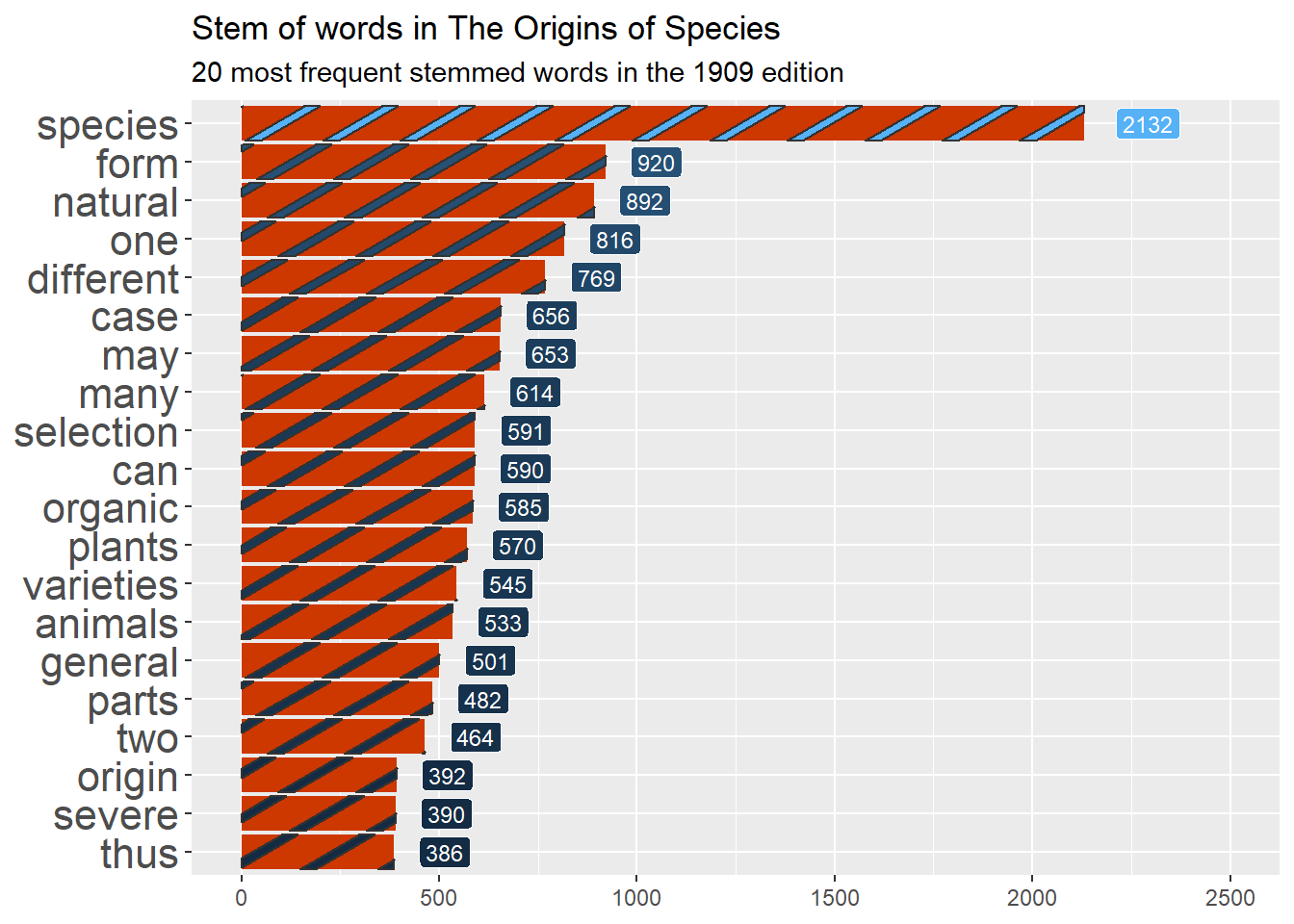
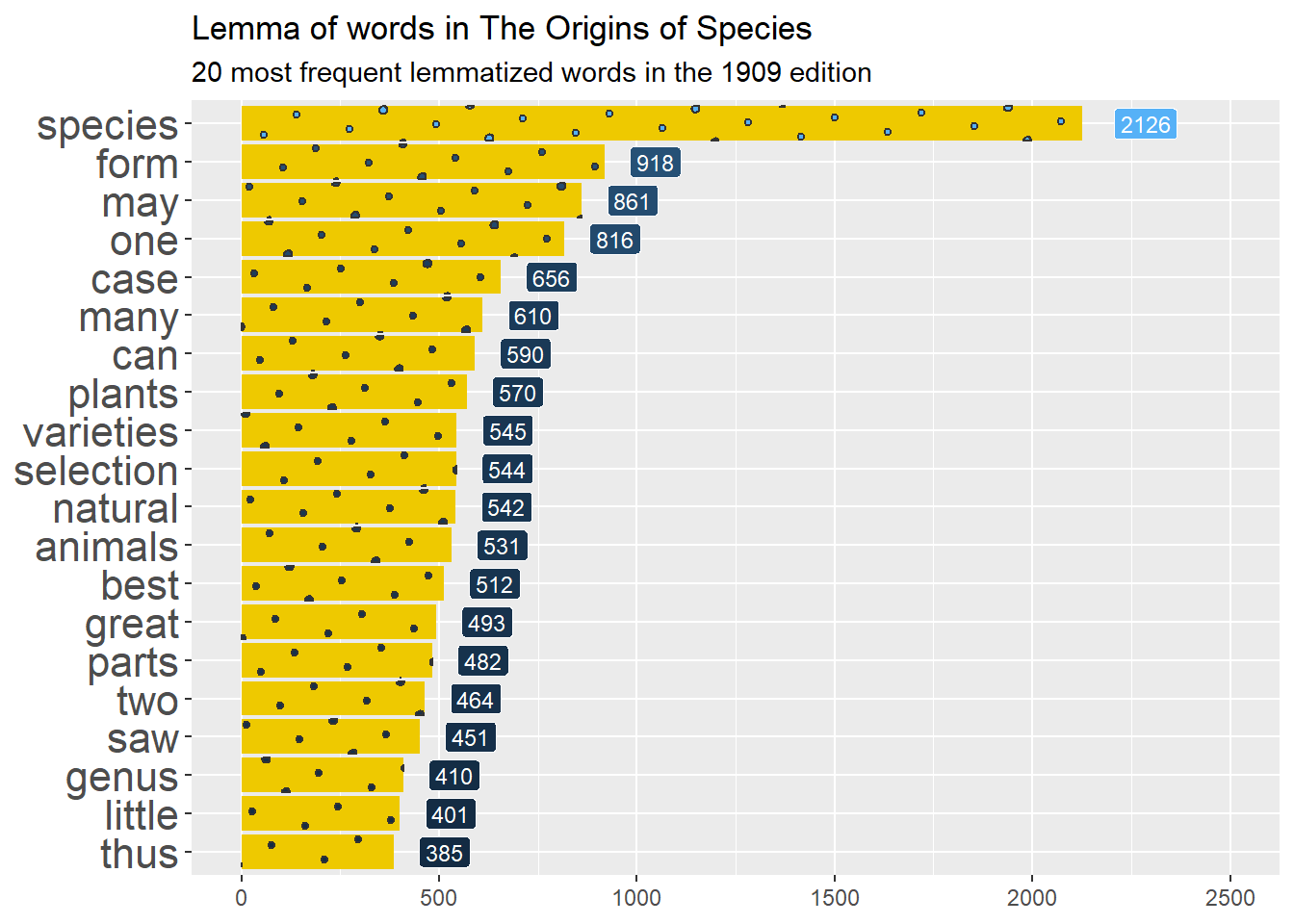
Finally, we will look at the stem of the remaining words, as we want to avoid duplicates from plurals and the like. For this we will use the SnowballC package, which has a handy function to extract the root of words. We also do lemmatization, or identifying the dictionary form of the words based on linguistics and grouping them together using the textstem package.
We won’t go into the details, but check the differences between the stem and lemma results below to pick your curiosity:
Click me!
library(pdftools)library(tidytext)library(tidyverse)library(hunspell)library(SnowballC)library(textstem)# Tokenization - Turn all text into a data frame of words ####toos_df <- the_origins_of_species |> tibble::as_tibble() |> tidytext::unnest_tokens(input ="value", output ="word", token ="words", to_lower =TRUE)# Stopwords - Remove them with anti_join ####stopwords::stopwords(language ="en")# Now let's remove all the stop words from our data and stem the text ####toos_df |> dplyr::anti_join(stopwords::stopwords(language ="en") |>as_tibble(),by=c("word"="value")) |> dplyr::mutate(stem = SnowballC::wordStem(word),lemma = textstem::lemmatize_words(word))
3
Make into a database
4
Tokenize into words using the unnest_tokens() function. We also make the text lower-case.
5
See the list of stopwords in each language
6
Remove all the stopwords from the list using anti_join(), which removes all words common in both datasets.
7
Identify the stem of each word, to avoid counting conjugation duplicates, and lemmatization that uses linguistics to create lemmas, the canonical or dictionary forms of word.
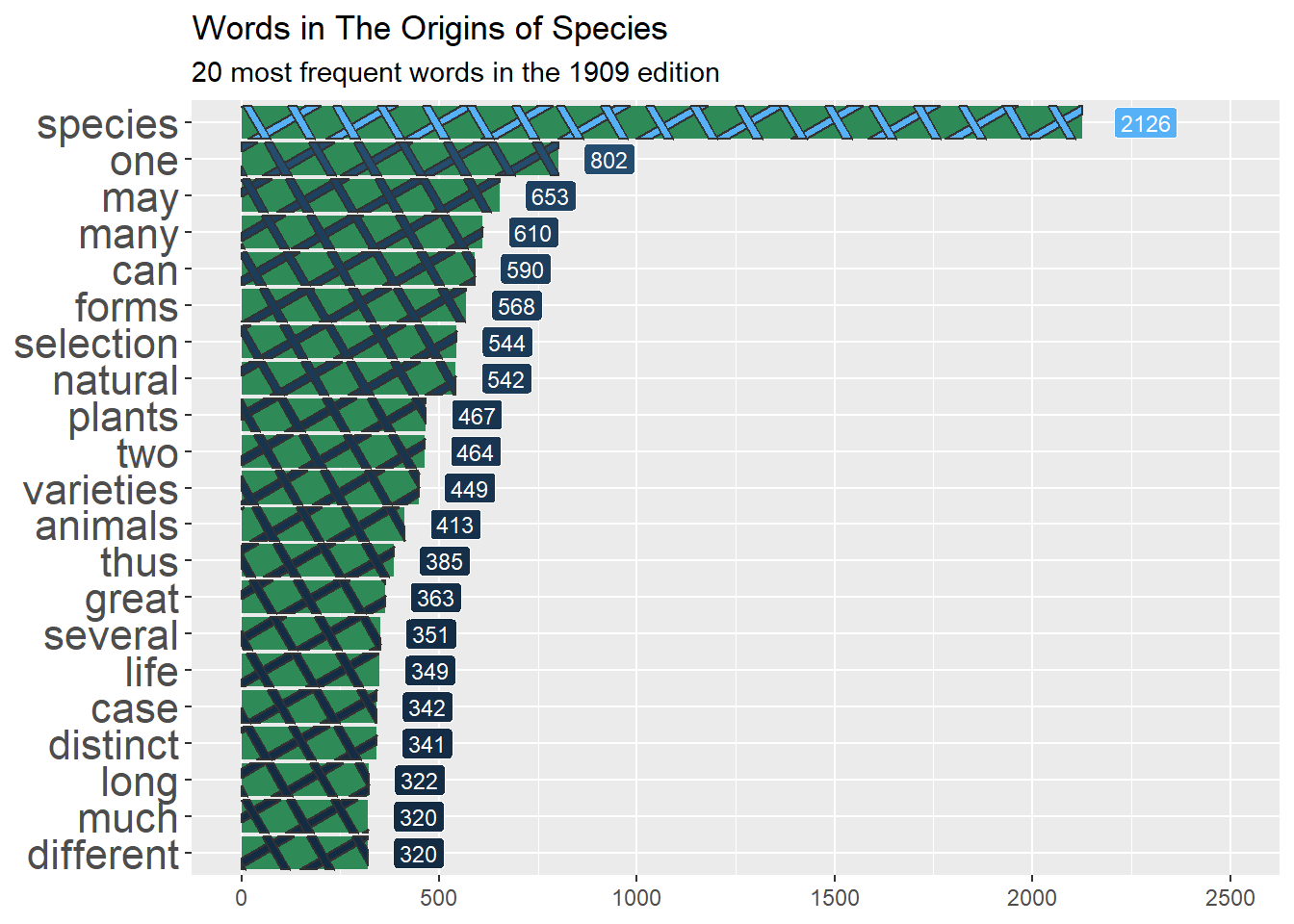
Now let’s see the result from the cleaning by plotting the frequency of the words that appear the most in the book using ggplot2 –for words, their stems and also their lemmas. We will start with the original data and, using the pipe, clean it, sort it, slice it and feed it to ggplot. In this case, we want bars/columns to represent the frequency of each word. We’ll use the package ggpattern to style the bars, so we use geom_col_pattern() with pattern options, and geom_label() to add the numeric frequency of the word next to each bar.
Compare the results below, and notice the differences:
Wordclouds are mostly decorative, they are not very informative. They are the pie charts of text data: There will always be a better way to convey the information, but people like them anyway.
To create a wordcloud, we only need to use one new geometry: geom_text_wordcloud(). As arguments we give the label for each word and the weight of the word based on the frequency. we can also change the area un which the wordcloud is created, using the scale_size_area() option and a 3-color diverging palette.
Use the geom_text_wordcloud() geometry to plot the wordcloud very easily, even adding a variable to weight the size by frequency in the text and color it with a palette.
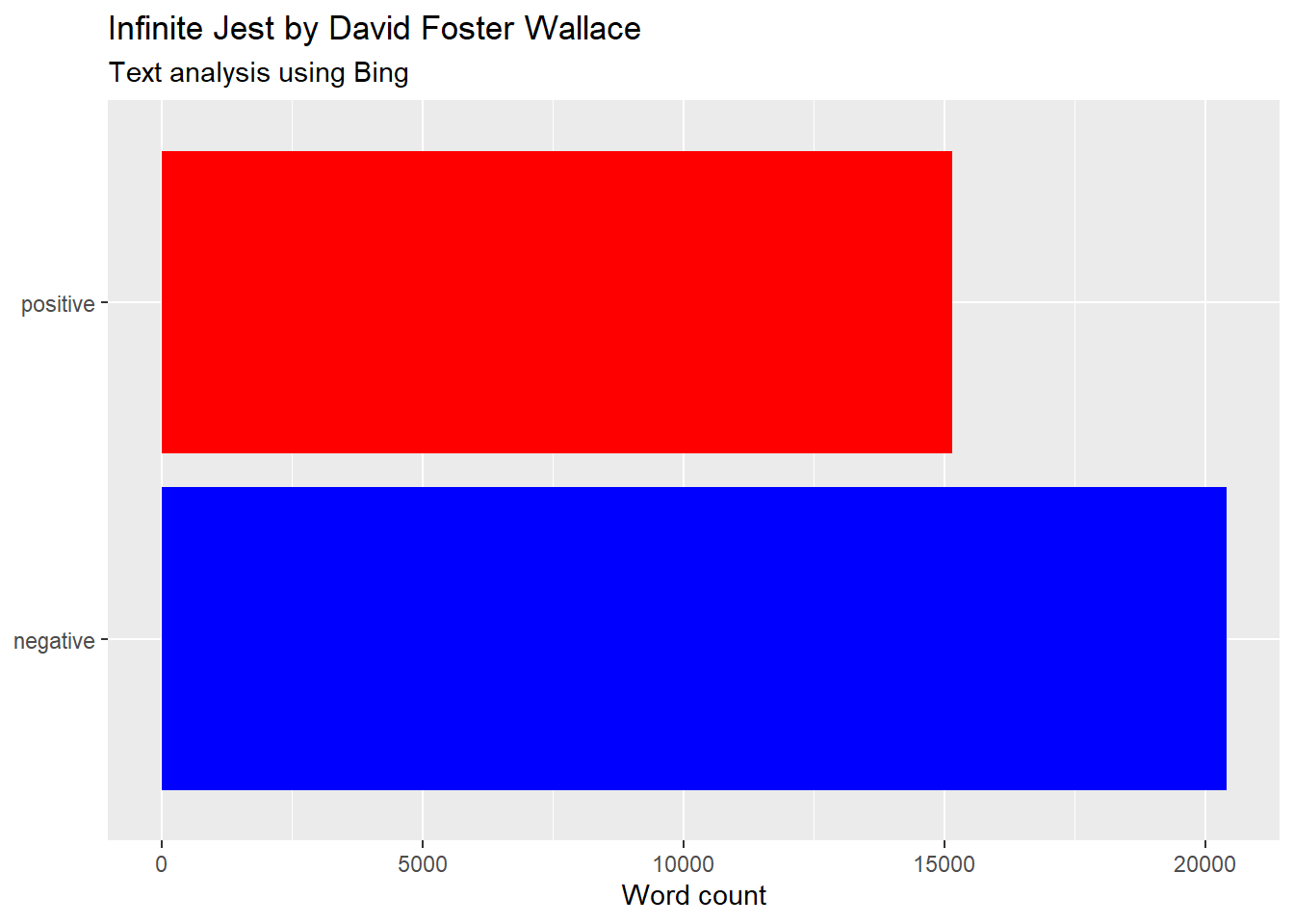
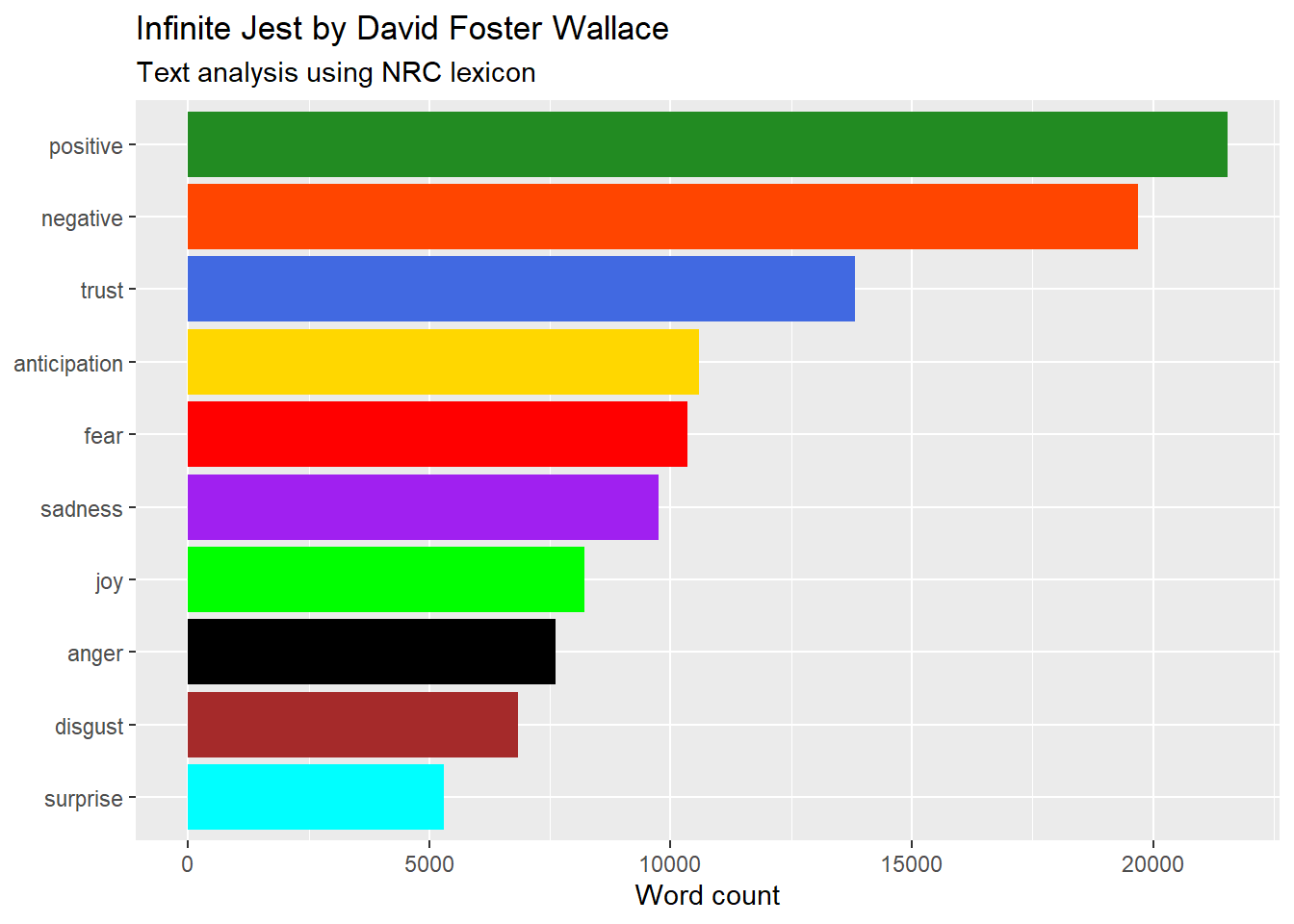
Sentiment analysis for Infinite Jest
Words have connotations that can be analysed numerically. Evaluating an opinion or emotion in text can be done using sentiment analysis, which we will do for another american novel: David Foster Wallace’s Infinite Jest. To do this, we just need to add a database with negative/positive identifiers for words in English and match them with the data from the book.
We’ll use the lexicon Bing to start, which gives either a single positive or negative association to a large set of words in English.
Click me!
library(textdata)library(tidytext)# Look at the list of words and +/- sentiment ####tidytext::get_sentiments("bing")
With the pipe workflow, we sequence all the steps we did before and join the sentiment lexicon to get a visual summary of the frequency of positive or negative words in this mammoth novel.
Tipdplyr helper functions
The dplyr package has some useful functions that regex text without a hassle: you can select variables or filter observations based on text.
starts_with: starts with a prefix (same as regex ‘^blah’)
ends_with: ends with a prefix (same as regex ‘blah$’)
contains: contains a literal string (same as regex ‘blah’)
matches: matches a regular expression (write regex here)
num_range: a numerical range like x01, x02, x03 (same as regex ‘x[0-9][0-9]’)
Erase all blank spaces using the squish function 11 Make into a nice tibble rectangular database
11
Tokenize words
12
Remove all stopwords using anti_join()
13
Join all words with sentiments using left_join()
14
Filter out all words without a sentiment joined to them
15
Group and summarise the count of words by sentiment
16
Pipe into ggplot
The positive/negative lexicon is not very interesting. There is another one called NRC1 which is more nuanced.
Let’s repeat the analysis using this lexicon and draw word frequencies by sentiment group, taking into account that words can have multiple sentiments and will be counted multiple times. Using scale_fill_manual() we can easily assign a color to each sentiment.
TipJoin us! Merging data with dplyr
Merging data between databases using dplyr is a joy, not a headache. There are several join functions that ease combining datasets based on common variables:
inner_join() returns only the matching rows from both datasets, keeping only the observations with common values in the specified variables.
left_join() returns all rows from the left dataset and the matching rows from the right dataset, keeping all observations from the left dataset and only the matching ones from the right dataset.
right_join() is similar to left_join(), but it keeps all observations from the right dataset and only the matching ones from the left dataset.
full_join() returns all rows from both datasets, keeping all observations from both datasets and filling in missing values with NAs when there is no match.
semi_join() returns only the rows from the left dataset that have a match in the right dataset, discarding observations without a match.
anti_join() returns all rows from the left dataset that do not have a match in the right dataset. It essentially removes the rows with matching values in the specified variables, keeping only the observations from the left dataset that have no corresponding match in the right dataset.
You can specify the columns for matching using the by argument within the chosen join function to specify the columns that should be used for matching. If you want to join based on a single column named “ID”, you would write: by = "ID". If you want to match on multiple columns, such as “ID” and “Date”, you would write: by = c("ID", "Date")).
Retrieve the sentiment lexicon NRC using the function get_sentiments()
19
Import the text into R
20
Erase all blank spaces
21
Make into a tibble database
22
Tokenize words
23
Remove all stopwords using anti_join()
24
Join all the sentiments using left_join(). There might be multiple matches, so add “multiple=”all”” so that all matches are joined, not only one.
25
Filter out all words without sentiment matched to them
26
Summarise words by sentiment
27
Notice how you can customise the colors using scale_fill_manual(). You can manually match a color to a value in the data using a simple vector where value=“color”.
Rejoinder: Narrative progression in Moby Dick 🐋
A fun application of sentiment analysis is tracking the frequency of words by sentiment from beginning to end of a novel. We’ll use Moby Dick as an example, showing with the help of girafe, how the relative frequency of each sentiment in the Bing lexicon changes throughout the novel between positive and negative words.
As you can see below, the book grows progressively more negative, as the cumulative word count by sentiment shows.
A cool application of text analysis, topic modelling, tries to answer a very practical question: Take two or more texts. How are they related to one another?
Imagine the following situation. Someone scrambles all chapters of all OECD reports written over the past year, leaving thousands of files without names or any indication of which report they belong to. You know how many reports there were originally and are tasked to stitch back together all reports. How would you do that?
Using statistical techniques over text data pulled from all the scrambled chapters, you can try to infer how each leftover document is similar in style, content, word frequency and other features of the text to try to estimate how likely it is that 2 documents belong to the same report.
We’ll do exactly this but not over OECD reports, because that would be too boring. So we’ll do it over scrambled chapters from classical works of fiction and non-fiction.
Let’s first make a mess of some literature.
Choosing which books to shuffle
Project Gutenberg holds many works of literature that don’t have copyright anymore and are ready for text analysis. We’ll choose some books, download them into R using the gutenbergr package, and then break them apart by chapter in order to use topic modelling to stitch them back together.
These are the books we’ll use:
The Picture of Dorian Gray by Oscar Wilde
The Prince by Niccolo Machiavelli
Pride and Prejudice by Jane Austen
War and Peace by Leo Tolstoy
On Liberty by John Stuart Mill
The Art of War by Sun Tzu
Click me!
# Download books ####library(gutenbergr)library(tidytext)library(tidyverse)# Save a list of all books into your environment ####pg_all <- gutenbergr::gutenberg_metadata# Books to break down with names and IDs ####shuffle_titles <-tribble(~title,~gutenberg_id,"The Art of War", 17405,"The Prince", 26253,"On Liberty", 34901,"Pride and Prejudice",1342,"War and Peace",2600,"The Picture of Dorian Gray",174 )# Download the books ####shuffle_books <- gutenbergr::gutenberg_works(gutenberg_id %in% shuffle_titles$gutenberg_id) |> gutenbergr::gutenberg_download(meta_fields ="title", mirror ="https://gutenberg.pglaf.org/")# Make sure all books were downloaded ####shuffle_books |> dplyr::distinct(title)
28
Create a tribble with the Gutenberg ID for each book
29
Download all the books. Use another mirror if the download does not work.
# A tibble: 5 × 1
title
<chr>
1 The Picture of Dorian Gray
2 Pride and Prejudice
3 War and Peace
4 The Art of War
5 On Liberty
Alternatively, you can read the plain text files for each book, as the gutenbergr mirrors might not work using the readLines function:
Click me!
# Add URL for plan text for each book ####shuffle_titles_url <-tribble(~title,~gutenberg_id, ~url,"The Art of War", 17405,"https://www.gutenberg.org/cache/epub/132/pg132.txt","The Prince", 26253,"https://www.gutenberg.org/cache/epub/57037/pg57037.txt","On Liberty", 34901,"https://www.gutenberg.org/cache/epub/34901/pg34901.txt","Pride and Prejudice",1342,"https://www.gutenberg.org/cache/epub/1342/pg1342.txt","War and Peace",2600,"https://www.gutenberg.org/cache/epub/2600/pg2600.txt","The Picture of Dorian Gray",174,"https://www.gutenberg.org/cache/epub/174/pg174.txt" ) # Get all text from the books ####shuffle_books <- shuffle_titles_url |> dplyr::mutate(text =map(url, ~readLines(.x, warn =FALSE))) |> tidyr::unnest(text)
Shuffling, breaking books apart
Now we carry out the shuffling: we identify book chapters and create a chapter indicator for each book. We then use it to break the books apart, and then break the chapters apart into words which we will model.
Create a variable that identifies the word chapter and counts to which chapter each line belongs to using the cumulative sum cumsum() function
32
Ungroup the data
33
Filter out the text before the first chapter
34
Using the unite() function we can create a new variable with the title and chapter columns called document
35
Unnest the tokens in the text column
36
Remove stopwords
37
Count variables and sort them with the count() function
What chapter belongs to which book? LDA all-at-once approach3
To see which chapters belong to which books, we will use a technique called Latent Dirichlet Allocation, LDA. This is a statistical model that estimates the probability of a particular word from a chapter to belong to a topic, and then we can use that probability across chapters to reassemble each book.
LDA works by assuming that, when writing a text, the author draws a mixture of topics: a set of weights that describe how prevalent each topic will be in the text. Given those weights, the author writes the actual text. For each word in the text, the author draws the word’s topic. Then, conditional on the topic, the word is drawn from a topic-specific distribution –a list of words. This topic-specific distribution is common across the documents and defines the rates at which words appear when discussing a particular topic.
LDA estimates two key probabilities: Word-Topic (\(\beta\)) and Document-Topic (\(\gamma\)). That is, it finds the mixture of words that is associated with each topic, and the mixture of topics that describes each document.
What is a topic? In LDA, topics are latent variables, variables we can’t observe, that capture the underlying theme or meaning of a set of words in a text. In LDA, a document is modeled as a mixture of latent topics, where each topic is a probability distribution over the words in the vocabulary. Topics are probability distributions of terms.
For instance, in news articles, a topic might represent the probability distribution over words such as politics, government, sports or election. In a scientific publication, topics might represent the probability distribution over words such as science, research and technology.
Topics are inferred by the LDA model, and the number of topics is usually specified by the modeler before training the model. LDA will group words together in the corpus, creating topics based on the co-occurrence of words in the documents. These inferred topics can be used for different downstream tasks such as document classification, which is what we’ll do.
flowchart LR
Words:::word-- Beta --> Topics:::topic -- Gamma --> Document:::doc
classDef word fill:#E4AD07
classDef topic fill:#CA0505
classDef doc fill:#E46507
Before estimating our model, we need to transform the data we tokenized into a Document Term Matrix, which is needed as an input for the function that actually estimates the model. This is easy enough using the cast_dtm() function.
Then we estimate our model. We use \(k = 6\) because we have 6 books, and run the model with the LDA() function from topicmodels:
Click me!
library(tidytext)library(tidyverse)library(topicmodels)library(scales)shuffle_dtm <- chapter_word |> tidytext::cast_dtm(document, word, n)# estimate LDAshuffle_lda <- topicmodels::LDA(shuffle_dtm,# As many topics as books, but we can include more if we wanted tok =length(unique(shuffle_titles$gutenberg_id)),# For reproduciblity control =list(seed =1234))
38
Create a document-term matrix from the chapter_word data frame using the cast_dtm() function. Look at the result
39
Use the LDA() function by providing the document-term matrix and the number of topics you want to model
40
k represents the number of topics.
41
We use a seed to make sure the results replicate
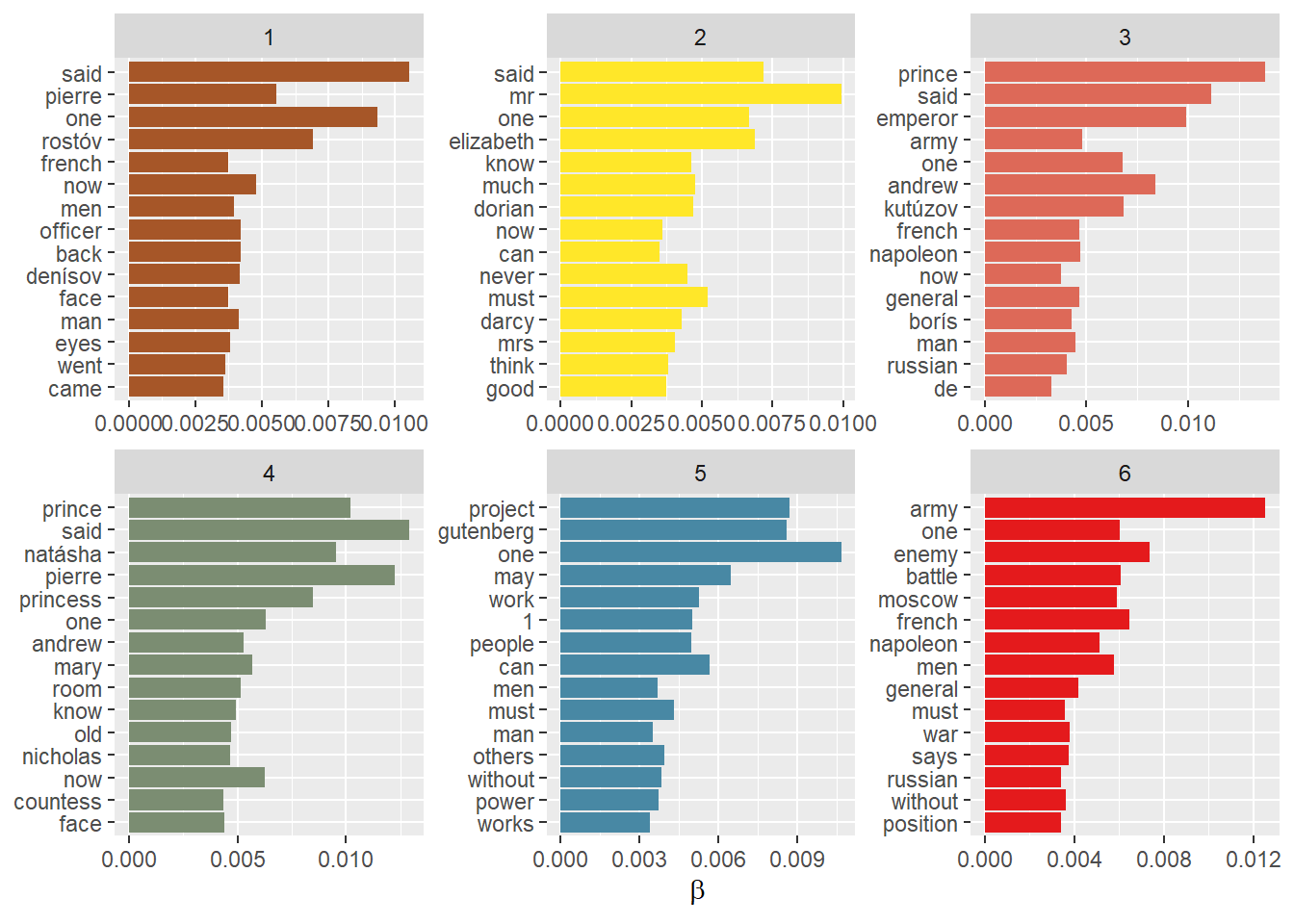
Let’s look at the words with the highest probabilities to below to each of the 6 topics. There are clearly some words from each book that are more salient in some topics. Let’s get serious and use all the model results.
Click me!
library(tidytext)library(tidyverse)library(topicmodels)library(scales)library(broom)# Plotbroom::tidy(shuffle_lda, matrix ="beta") |> dplyr::group_by(topic) |> dplyr::slice_max(order_by = beta, n =15) |>ggplot(aes(x= term |>reorder(beta), y= beta, fill=topic)) +geom_col() +coord_flip()+scale_fill_distiller(palette="Set1")+facet_wrap(~topic, scales ="free") +labs(x =NULL, y =expression(beta))+theme(legend.position ="none")
42
Extract the \(\beta\) probabilities from the model, word-topic probabilities.
Working with word-topic (\(\beta\)) and topic-book (\(\gamma\)) probabilities
\(\beta\) controls the distribution of words within a topic. It is a Dirichlet prior on the per-topic word distributions. In other words, it represents the probability of a specific word being present in a topic. A higher beta value will result in a more diverse set of words within a topic, while a lower beta value will lead to a more focused set of words.
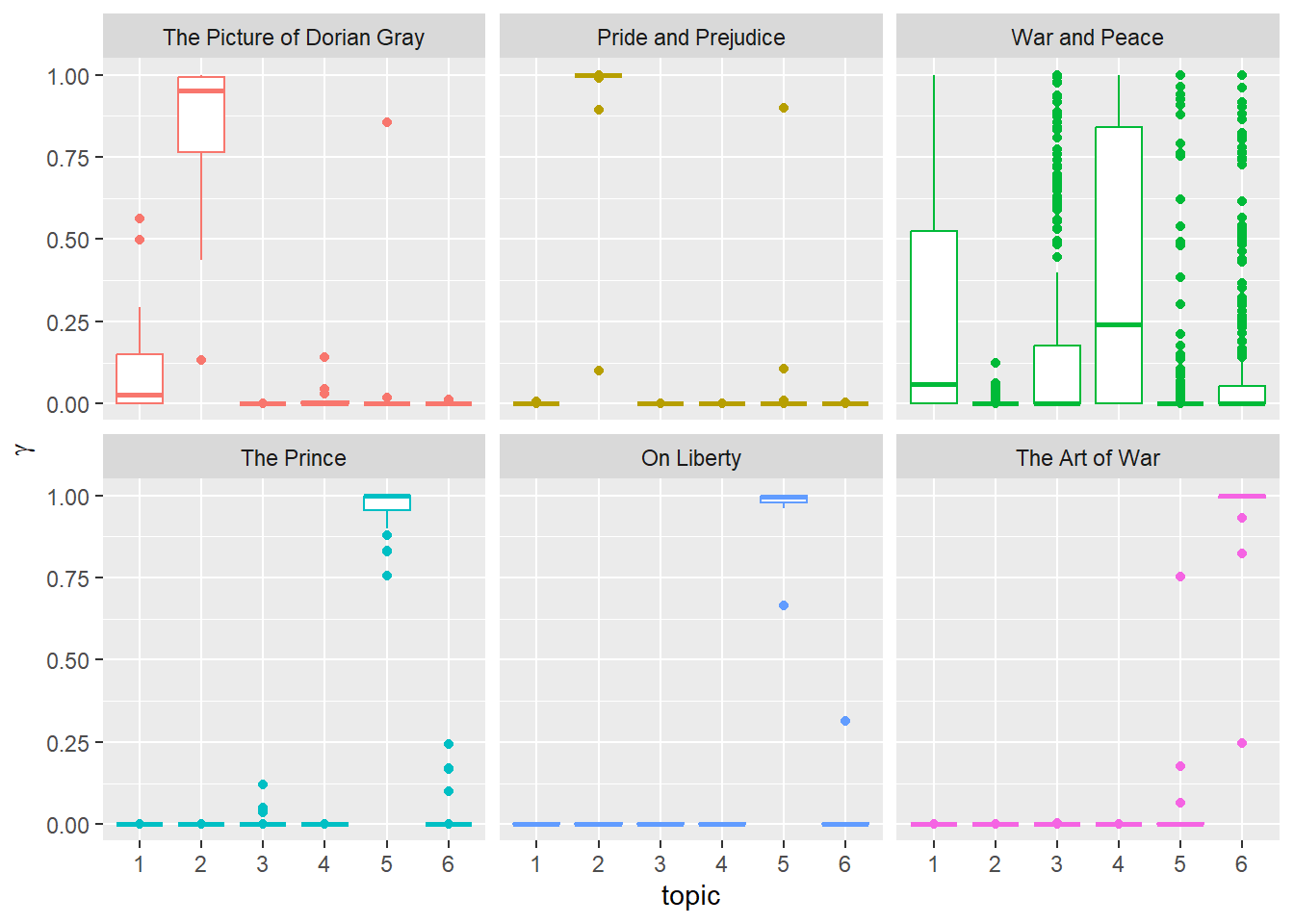
\(\gamma\) controls the distribution of topics within a document. It is a Dirichlet prior on the per-document topic distributions. It governs the probability of a specific topic being present in a document. A higher gamma value will result in a more diverse set of topics within a document, while a lower gamma value will lead to a more focused set of topics.
We extract model results in tidy format using the broom package tidy() function, which extracts model results in our favorite format. Let’s look in detail at model results for both key parameters.
We can see that \(\gamma\) worked well for some books, not so much for others.
Let’s look more closely at the classification –where it succeeded and where it failed.
Did it work?
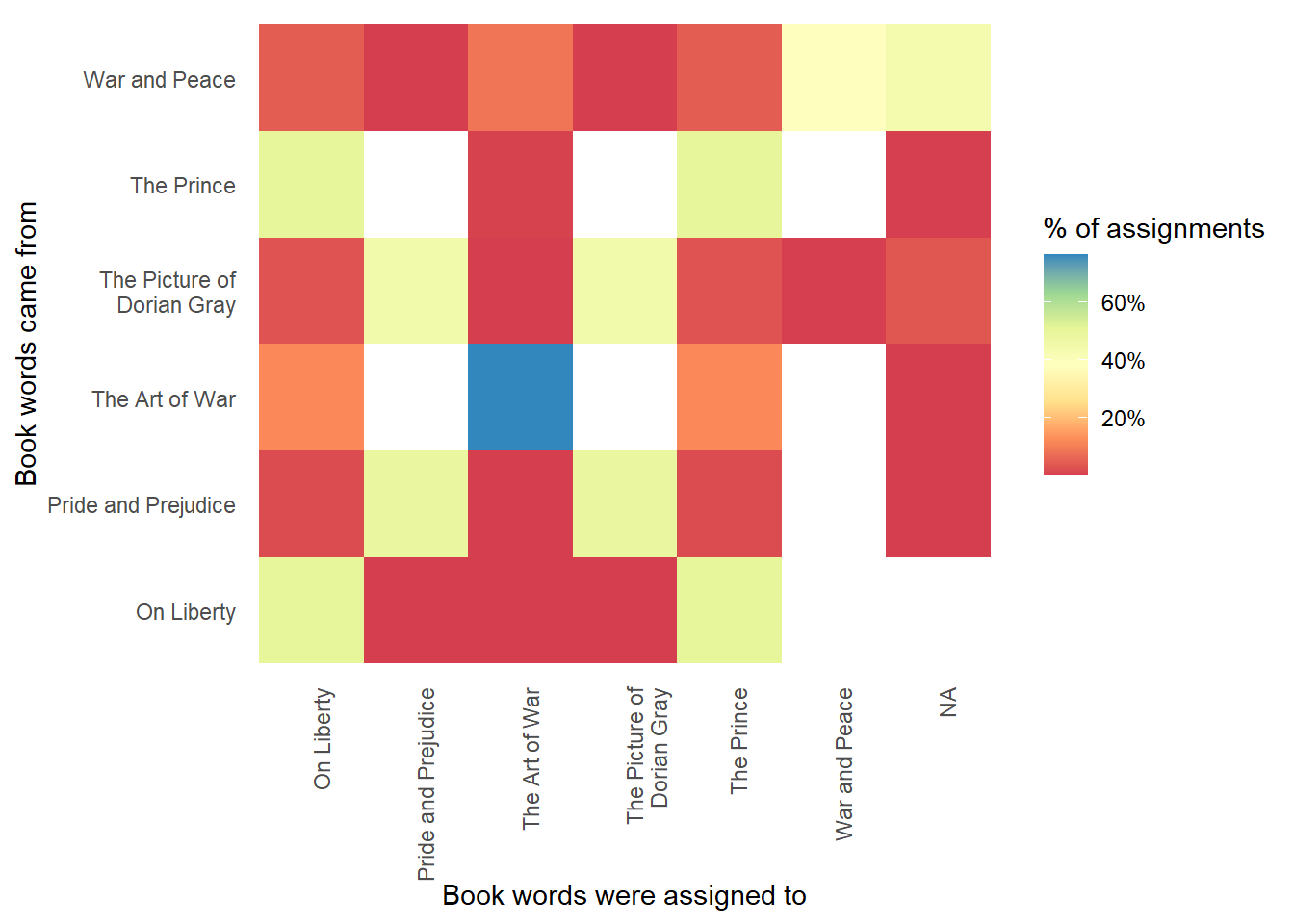
To know how well the topic classification worked, we build a tile grid to relate how many chapters from each book were correctly classified into the book they originated from.
Now the picture is clearer. Some books, the shortest and distinct from the others, were for the most part correctly classified.
To get better results from this approach we need to delve deeper into the tuning parameters of the model or try an entirely different text-data approach.
Click me!
library(tidytext)library(tidyverse)library(topicmodels)library(scales)# Save chapter classifications ####chapter_classifications <- broom::tidy(shuffle_lda, matrix ="gamma") |> tidyr::separate(document, c("title", "chapter"), sep ="_", convert =TRUE) %>% dplyr::group_by(title, chapter) %>% dplyr::slice_max(gamma) %>% dplyr::ungroup()# Save most likely topics for each book ####book_topics <- chapter_classifications %>% dplyr::count(title, topic) %>% dplyr::group_by(title) %>% dplyr::slice_max(n, n =1) %>% dplyr::ungroup() %>% dplyr::transmute(consensus = title, topic)# Join the results ####chapter_classifications %>% dplyr::left_join(book_topics, by ="topic") %>% dplyr::filter(title != consensus)# Add Document Term Matrix data to results and join book classifications ####assignments <- broom::augment(shuffle_lda, data = shuffle_dtm) |> tidyr::separate(document, c("title", "chapter"), sep ="_", convert =TRUE) %>% dplyr::left_join(book_topics, by =c(".topic"="topic"))# Visualise the result ####assignments %>% dplyr::count(title, consensus, wt = count) %>% dplyr::mutate(across(c(title, consensus), ~str_wrap(., 20))) %>% dplyr::group_by(title) %>% dplyr::mutate(percent = n /sum(n)) %>%ggplot(aes(consensus, title, fill = percent)) +geom_tile() +scale_fill_distiller(palette ="Spectral", direction=1,label =percent_format()) +theme_minimal() +theme(axis.text.x =element_text(angle =90, hjust =1),panel.grid =element_blank()) +labs(x ="Book words were assigned to",y ="Book words came from",fill ="% of assignments")
46
Save the most-likely result as a consensus variable
47
Join the consensus result to the data
48
Notice across() which facilitates applying a function to multiple columns
# A tibble: 158 × 5
title chapter topic gamma consensus
<chr> <int> <int> <dbl> <chr>
1 On Liberty 1 5 0.957 The Art of War
2 On Liberty 2 5 0.971 The Art of War
3 On Liberty 3 5 0.975 The Art of War
4 On Liberty 4 5 0.975 The Art of War
5 On Liberty 5 5 0.994 The Art of War
6 On Liberty 6 5 1.000 The Art of War
7 On Liberty 7 5 0.992 The Art of War
8 On Liberty 8 5 1.000 The Art of War
9 On Liberty 9 5 1.000 The Art of War
10 On Liberty 10 5 1.000 The Art of War
# ℹ 148 more rows
(You’ll learn how to do this later)
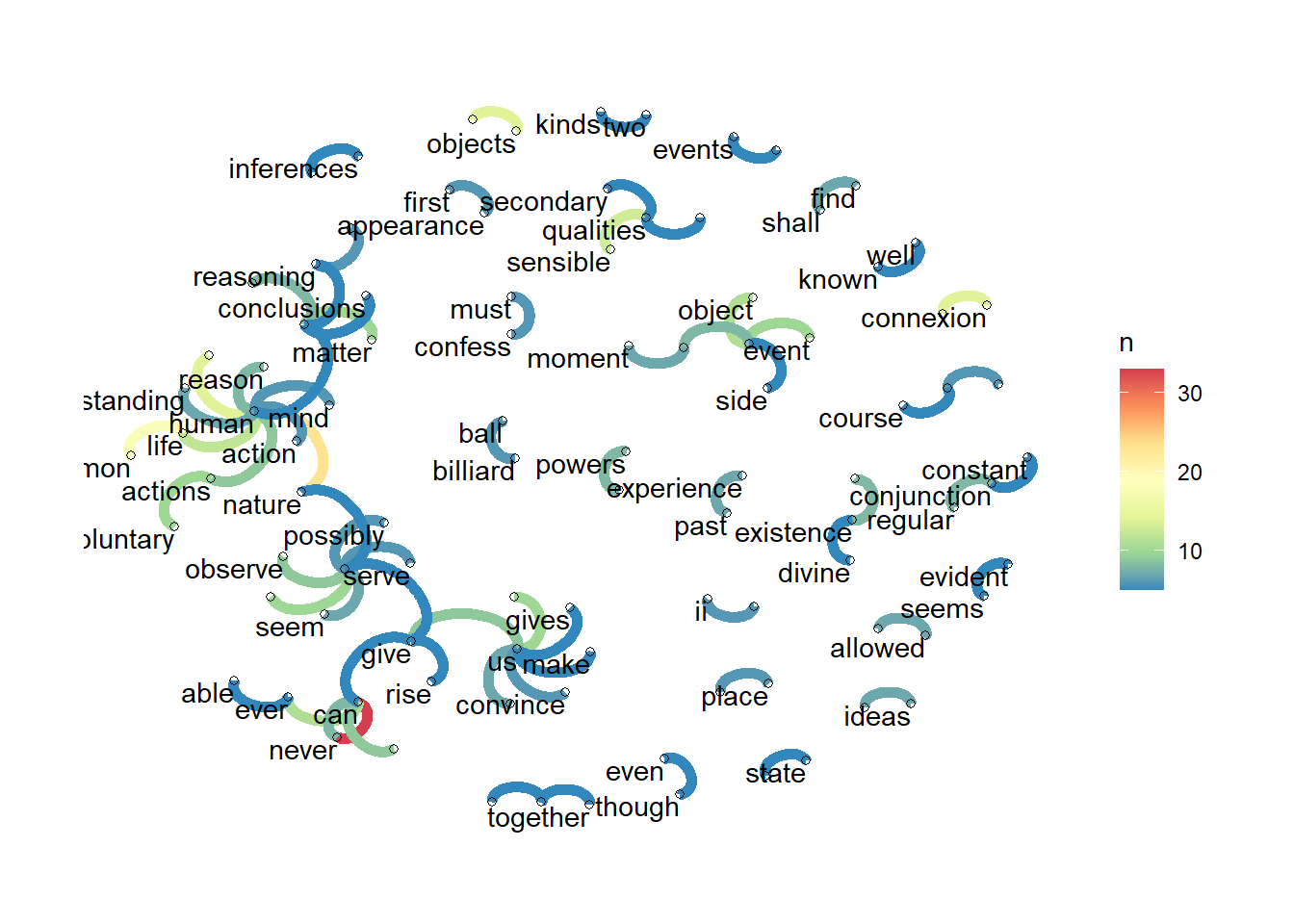
Bonus track: Networks of n-grams in the work of David Hume
There are many types of relational analysis you can do with text. An interesting one is how expressions, measured as n-grams (adjacent words), are related to one another using networks. We’ll use David Hume’s An Enquiry Concerning Human Understanding to illustrate, which we will import from Project Gutenberg.
We will tokenize differently using the n-grams output option in the unnest_tokens() function. We need to decide how many adjacent words will be tokenized, so for ease we will do pairs of words.
After we tokenize and count, we need to turn each pair of words into a network, which is easy using the igraph package and then well use the ggraph package to visualise it. Networks are made of nodes and edges, and in this case an n-gram of two words means two nodes are connected to each other by an edge. Using the graph_from_data_frame() function, we can turn a tibble made of pairs of words into a network.
Look at the code below that shows all the steps, from tokenizing to plotting the network. Notice the changes in ggraph, like the layout (an algorithm that places nodes in the graph according to their properties) and the geoms –for both edges and nodes.
But also look at the results. The n-grams show relationships between key concepts in this important work on epistemology, like natural events, or how reasoning is connected to observation, the mind and matter.
Click me!
library(ggraph) # ggplot2 tools for networkslibrary(tidygraph) # Tidy objects for networkslibrary(igraph) # the workhorse for network analysis in Rlibrary(gutenbergr) # To import books from Project Gutenberglibrary(tidytext)library(tidyverse)library(RColorBrewer)library(viridis)gutenbergr::gutenberg_download(gutenberg_id =9662, mirror ="http://mirrors.xmission.com/gutenberg/") |> tibble::as_tibble() |> tidytext::unnest_tokens(input ="text",output ="ngrams",n=2,token ="ngrams",to_lower =TRUE) |> tidyr::separate(ngrams, into =rep(paste0("word_",1:2), sep =" ")) |> dplyr::filter(!word_1 %in% stopwords::stopwords(language ="en"),!word_2 %in% stopwords::stopwords(language ="en")) |> dplyr::filter(nchar(word_1) >1,nchar(word_2) >1) |> dplyr::count(word_1,word_2,sort =TRUE) |> dplyr::slice_max(order_by = n, n=50) |> igraph::graph_from_data_frame() |> ggraph::ggraph(layout="fr")+ ggraph::geom_edge_arc(aes(edge_color=n), edge_width =2)+ ggraph::geom_node_point(shape=1)+ ggraph::geom_node_text(aes(label = name), vjust =1, hjust =1, check_overlap =TRUE)+ ggraph::scale_edge_color_distiller(palette="Spectral")+theme_graph()
49
We now create n-grams of length 2, all combinations of 2 consecutive words
50
Separate the n-grams to remove stopwords
51
Remove all stopwords and single-letter words
52
Count and keep most frequent n-grams
53
Turn data frame into igraph object to build a network using the graph_from_data_frame() function
54
Use ggraph with specified layout
55
Graph the edges or links
56
Graph the nodes and labels them
57
Clean up with theme made for networks and put a color scale on the connections
🏗️ Practice 3: Project Gutenberg
NoteEasy
Install the gutenbergr package install.packages("gutenbergr")
Pick a book from the library and download it to R
Carry out whichever sentiment analysis you prefer for the book and plot it
ImportantIntermediate
Carry our sentiment analysis for a book of your choice using all sentiment lexicons available in the get_sentiments() function: AFINN, NRC, Bing and loughran. Describe each result and the differences between them.
Write a function that downloads and cleans the text of any book in Project Gutenberg
Write a function that does sentiment analysis of any book in Project Gutenberg
CautionSolution:
Click me!
library(gutenbergr)library(tidytext)library(tidyverse)# Download the descent of man - Charles Darwin ####gutenbergr::gutenberg_download(gutenberg_id =34967, mirror ="http://mirrors.xmission.com/gutenberg/") |> tidytext::unnest_tokens(word, text) |> dplyr::anti_join(stopwords::stopwords(language ="en") |>as_tibble() |> dplyr::rename(word=1),by="word") |> dplyr::left_join(get_sentiments("afinn"), by="word") |> dplyr::group_by(value) |> dplyr::mutate(n =n(),p = n/sum(n),c =case_when(value<0~"Negative", value==0~"Neutral", value>0~"Positive") |>factor()) |>ggplot(aes(x=value,y=n,color=c))+geom_col(show.legend =FALSE)+geom_vline(xintercept =0)+scale_x_continuous(breaks=seq(from=-5,to=5,by=1))+scale_color_brewer(palette ="Set1")+annotate("text",x=-4,y=1000000, label ="Negative", color ="red")+annotate("text",x=4,y=1000000, label ="Positive", color ="blue")+labs(title ="The Descent of Man (Charles Darwin, 1871)",subtitle ="Sentiment analysis",x="AFINN lexicon",y="Word frequency",caption ="Source: R4DEV workshop")# Through a function ####book_sentiments <-function(author_name,book_name) {# Extract ID gutenbergr::gutenberg_works() |> dplyr::filter(str_detect(author,author_name), str_detect(title,book_name)) |> dplyr::select(gutenberg_id) |>as.numeric() |># Download book gutenbergr::gutenberg_download(mirror ="http://mirrors.xmission.com/gutenberg/") |># unnest tokens tidytext::unnest_tokens(word, text) |># Exclude stopwords dplyr::anti_join(stopwords::stopwords(language ="en") |>as_tibble() |> dplyr::rename(word=1),by="word") |># Join sentiments dplyr::left_join(get_sentiments("afinn"), by="word") |> dplyr::group_by(value) |> dplyr::mutate(n =n(),p = n/sum(n),c =case_when(value<0~"Negative", value==0~"Neutral", value>0~"Positive") |>factor()) |># Plot resultsggplot(aes(x=value,y=n,color=c))+geom_col(show.legend =FALSE)+geom_vline(xintercept =0)+scale_x_continuous(breaks=seq(from=-5,to=5,by=1))+scale_color_brewer(palette ="Set1")+annotate("text",x=-4,y=1000000, label ="Negative", color ="red")+annotate("text",x=4,y=1000000, label ="Positive", color ="blue")+labs(title =paste0("Sentiment analysis for ",print(book_name)," by ",print(author_name)), subtitle ="Book from Project Gutenberg",x="Sentimen AFINN",y="Word frequency",caption ="Source: R4DEV workshop")}# Plot a book based on the author name and title ####book_sentiments("Hume, David","A Treatise of Human Nature")