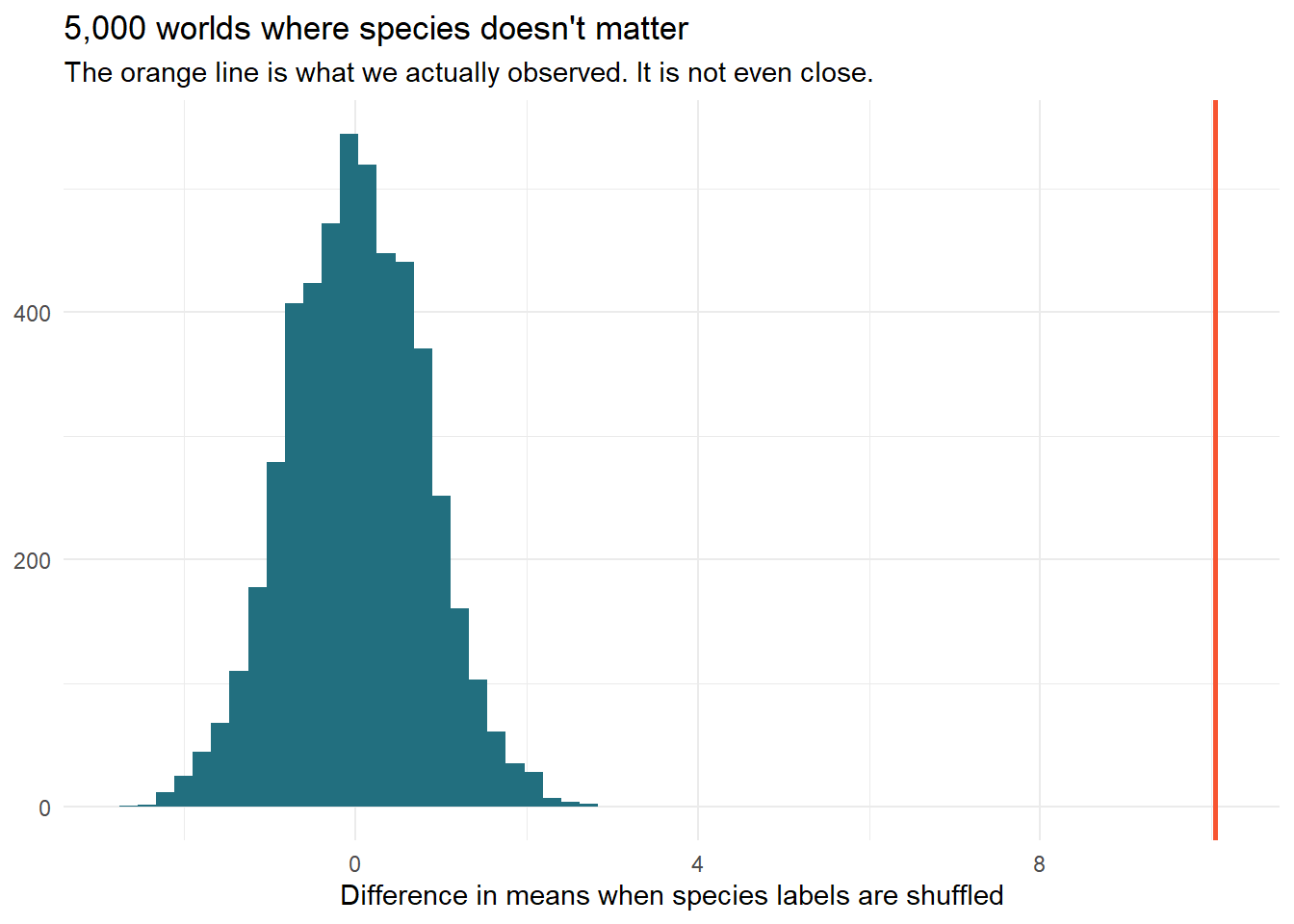Permutation, the bootstrap, and what a p-value actually says
statistics
inference
bootstrap
infer
p-value
All of hypothesis testing is one idea: build a world where nothing is going on, simulate it, and ask if your data would be surprising there. Learn it by shuffling with the tidyverse, then industrialise it with infer.
Author
Nelson Amaya
Published
July 2, 2026
Modified
July 18, 2026
“To consult the statistician after an experiment is finished is often merely to ask him to conduct a post mortem examination. He can perhaps say what the experiment died of.” –Ronald A. Fisher
PART I: One idea wearing twenty names
Open any statistics textbook and you find a zoo: t-tests, chi-squared tests, ANOVA, Mann-Whitney, each with its own formula, table and existence conditions. Here is the secret the zoo hides1: they are all the same test, and you already have the tools to run it, because the previous session taught you to simulate sampling distributions.
Level: Intermediate · Time: ~45 min · Prerequisites: Embrace the noise · Tools: infer, dplyr, ggplot2
You will learn to
See permutation testing, the bootstrap and named tests (t-test, chi-squared, …) as one idea wearing different names.
Build a null world by shuffling data, and ask whether your observed data would be surprising there.
Run a permutation test and a bootstrap interval by hand with dplyr, then industrialise both with infer.
State honestly what a p-value does and does not mean.
The one test:
Compute a statistic from your data –a difference in means, a correlation, anything.
Build a null world: a version of reality where the effect you’re testing does not exist.
Simulate that world many times, computing the same statistic each time.
Ask: where does my real statistic fall in that distribution of nothing-going-on?
If your number sits comfortably in the middle of what nothing-going-on produces, you have learned nothing. If it sits in the far tail, the boring explanation strains –that tail probability is the infamous p-value.
Let’s run it on real penguins, imported straight from the web as this workshop likes it:
Now the null world. If species had nothing to do with bill length, the species labels would be arbitrary stickers –so we can build that world by shuffling the stickers and leaving the bills alone:
Show the code
set.seed(2024)null_world <-tibble(replicate =1:5000) |> dplyr::mutate(diff = purrr::map_dbl(replicate, \(i) { penguins |> dplyr::mutate(species =sample(species)) |> dplyr::summarise(m =mean(bill_length_mm), .by = species) |> dplyr::summarise(d = m[species =="Chinstrap"] - m[species =="Adelie"]) |> dplyr::pull(d) }) )null_world |>ggplot(aes(diff)) +geom_histogram(bins =60, fill ="#226F7F") +geom_vline(xintercept = observed_diff, color ="#F75431", linewidth =1) +labs(x ="Difference in means when species labels are shuffled",y =NULL,title ="5,000 worlds where species doesn't matter",subtitle ="The orange line is what we actually observed. It is not even close." ) +theme_minimal()
1
sample(species) with no other arguments shuffles the column –every penguin keeps its bill, gets a random label. This single line is the null hypothesis, written in R instead of Greek.
The verdict needs no formula: in 5,000 label-shuffled worlds, the biggest difference noise ever produced is a fraction of what we observed. The p-value is the share of null worlds at least as extreme as reality:
Show the code
mean(abs(null_world$diff) >=abs(observed_diff))
[1] 0
Zero out of 5,0002. A t-test would have told you the same thing through a formula –now you know what the formula is estimating.
PART III: The same machine, industrialized –infer
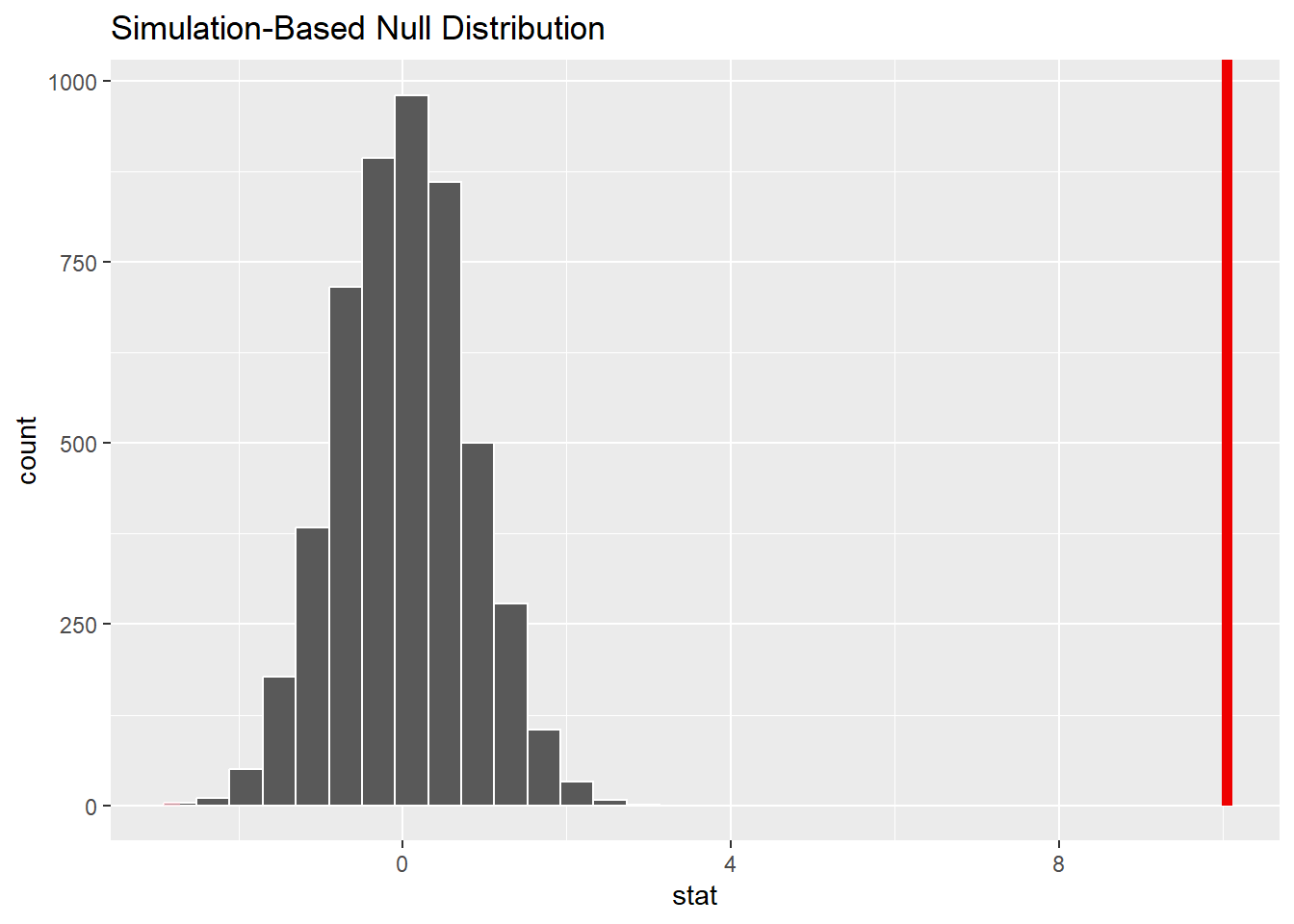
The infer package (tidymodels family) turns the four steps into four verbs –specify(), hypothesize(), generate(), calculate()– so the code reads like the logic:
Show the code
library(infer)set.seed(2024)null_dist <- penguins |> infer::specify(bill_length_mm ~ species) |> infer::hypothesize(null ="independence") |> infer::generate(reps =5000, type ="permute") |> infer::calculate(stat ="diff in means",order =c("Chinstrap", "Adelie"))null_dist |> infer::visualize() + infer::shade_p_value(obs_stat = observed_diff, direction ="two-sided")
1
The statistic’s recipe: outcome ~ grouping.
2
The null world: species and bill length are independent.
3
Build it 5,000 times, by permutation –our shuffle, industrialized.
4
Which statistic to track. Change "diff in means" to "diff in medians", "t", "Chisq"… and you have replaced half the textbook zoo without learning a new formula.
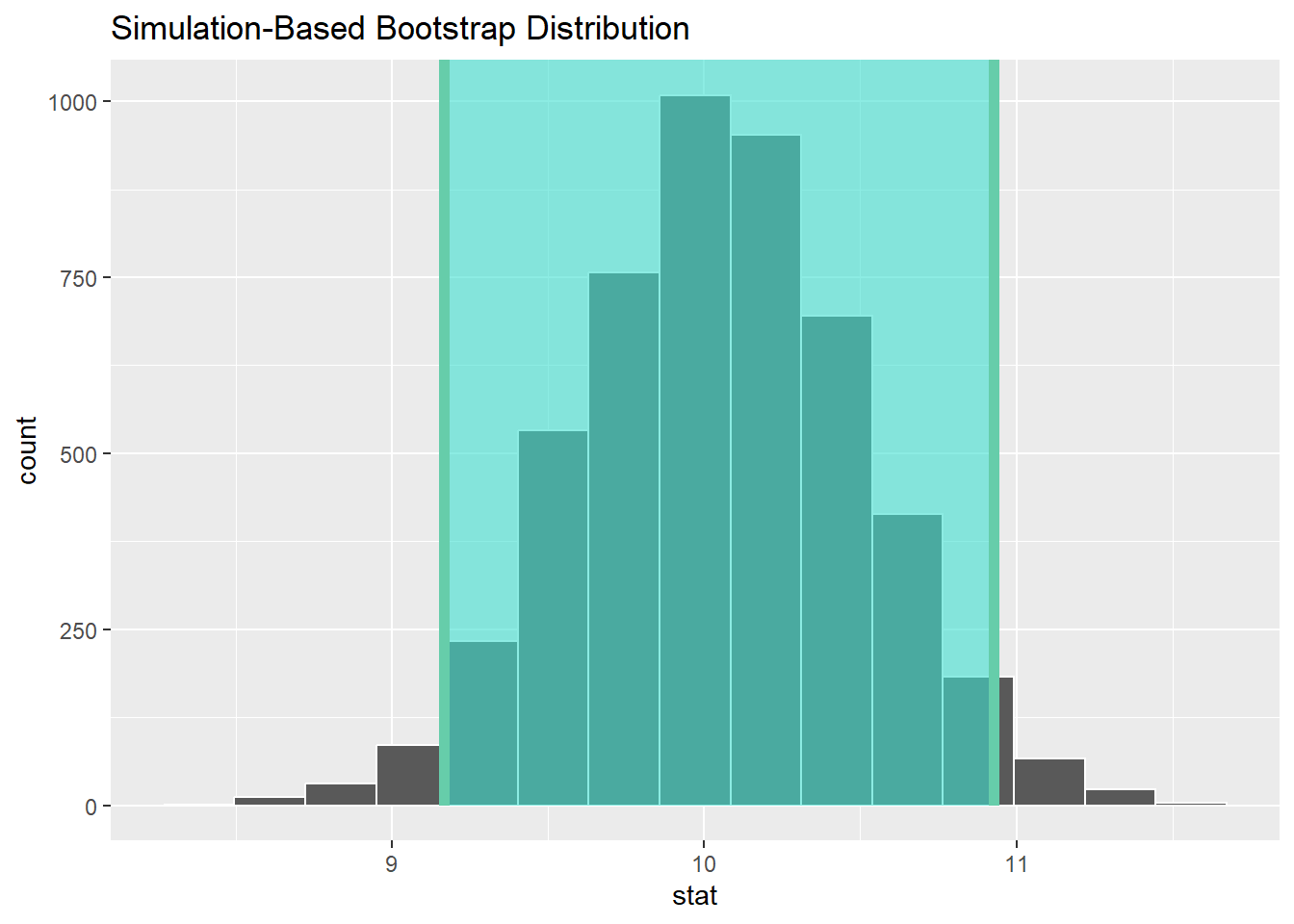
Bootstrap: the other side of the same coin
Permutation destroys a relationship to test it. The bootstrap does the reverse: it preserves the data and resamples it (with replacement) to measure how much your estimate wobbles –a confidence interval, without algebra:
Same pipeline, two changes: no hypothesize() (we’re estimating, not testing) and type = "bootstrap" (resample rows with replacement instead of shuffling labels).
Read it as: “if we could rerun this study endlessly, 95% of intervals built this way would capture the true difference.” Notice what the interval gives you that the p-value doesn’t: a magnitude with uncertainty, not just a verdict. Prefer it in almost every writeup.
PART IV: What the p-value is not
The p-value may be the most misquoted number in science, enough that the American Statistical Association issued a formal statement about it. Tattoo the correct reading somewhere: the probability of data at least this extreme, assuming nothing is going on. It is not:
The probability the null hypothesis is true –that question needs Bayes, the last stop of this track.
The probability the finding replicates.
A measure of importance –with n large enough, a difference of 0.1mm in bill length becomes “significant” while mattering to no penguin.
And one misuse you can now demonstrate to yourself, rather than take on faith. Test twenty hypotheses where nothing –truly nothing– is going on:
Both groups drawn from the same distribution: the null hypothesis is true by construction, twenty times. Yet significance arrives anyway –at 5% error per test, twenty tests make a false alarm more likely than not. This is the green jelly bean problem, and it is why “we tested many things and report the ones that worked” is not evidence, it’s arithmetic.
The jelly-bean trap doesn’t require running twenty literal tests. Choosing which outcome to measure, which subgroups to inspect, which observations count as outliers –each choice is a fork, and enough forks guarantee a “finding”. The defence is the discipline this workshop has preached from session 1: decide your analysis before looking, write it as code, version it. A committed script is a pre-registration you gave yourself.
TipExercises 🏋️
Rerun the permutation test with stat = "diff in medians". Does the conclusion survive a change of statistic? (Robust findings usually do.)
Use the full penguins data to test whether Gentoo and Adelie differ in flipper_length_mm, start to finish with infer.
Shrink the data: dplyr::slice_sample(n = 10, by = species) before the pipeline. What happens to the width of the bootstrap interval? Connect this to the \(\sqrt{n}\) rule from the previous session.
Simulate the forking-paths trap: generate one fake dataset with a null effect and 10 outcome variables; test all ten; report “the significant one”. Then explain, in one sentence, to your former self why this felt like science.
Key takeaways
Every named hypothesis test is the same idea: simulate a null world, then check if your data would be surprising there.
Permutation tests and bootstrap intervals answer different questions – is there an effect, and how big is it – and infer runs both with the same grammar.
Testing many things and reporting the ones that worked is not evidence, it’s arithmetic (the garden of forking paths).
Deciding your analysis before looking, and writing it as versioned code, is the practical defence against forking paths.
The framing is Allen Downey’s, from his classic post “There is still only one test”. The zoo of named tests exists because before computers, each special case needed its own hand-derivable algebra. You have a computer.↩︎
Which we honestly report as p < 1/5000, not p = 0 –our simulation just wasn’t big enough to see an event that rare.↩︎
Citation
BibTeX citation:
@online{amaya2026,
author = {Amaya, Nelson},
title = {There Is Only One Test 🃏},
date = {2026-07-02},
url = {https://r4dev.netlify.app/sessions_thinking/02-inference/02-inference},
langid = {en}
}